Haiku 和 jax2tf
目录
交互式在线版本: ![]()
Haiku 和 jax2tf#
jax2tf 是一个高级 JAX 功能,支持将 JAX 程序暂存为 TensorFlow 图。
如果您想与现有的 TensorFlow 代码库或工具集成,这是一个有用的功能。在本教程中,我们将演示如何在 Haiku 中定义一个简单的模型,将其转换为 TensorFlow 的 tf.Module,然后对其进行训练。
然后,我们将模型保存为 TensorFlow SavedModel,以便以后可以在其他 TensorFlow 程序中使用。
[1]:
!pip install dm-tree dm-sonnet tensorflow tensorflow_datasets ipywidgets matplotlib >/dev/null
[2]:
import haiku as hk
import jax
import jax.numpy as jnp
from jax.experimental import jax2tf
import sonnet as snt
import tensorflow as tf
import tree
在 JAX 中定义你的模型#
首先,我们需要使用 Haiku 和 JAX 定义我们的模型。对于 MNIST,我们可以使用像 MLP 这样的简单模型。
我们使用 JAX 初始化模型并获取初始参数值。如果您愿意,您可以继续使用 JAX 训练您的模型,但在本例中,我们将在 TensorFlow 中进行训练。
[3]:
def f(x):
net = hk.nets.MLP([300, 100, 10])
return net(x)
f = hk.transform(f)
rng = jax.random.PRNGKey(42)
x = jnp.ones([1, 28 * 28 * 1])
params = f.init(rng, x)
WARNING:absl:No GPU/TPU found, falling back to CPU. (Set TF_CPP_MIN_LOG_LEVEL=0 and rerun for more info.)
转换为 TensorFlow#
TensorFlow 附带了一个模块抽象,它支持收集模型参数等常见任务。
Sonnet 是一个 tf.Module 子类的库,包括常见的 NN 层、优化器和一些指标。Sonnet 是一个与 Haiku 同一个团队开发的姊妹库。
我们将使用 Sonnet 的模块类来实现一些不错的 name_scope,稍后我们将使用 Sonnet 中实现的 Adam 优化器以及一些实用函数。
[4]:
def create_variable(path, value):
name = '/'.join(map(str, path)).replace('~', '_')
return tf.Variable(value, name=name)
class JaxModule(snt.Module):
def __init__(self, params, apply_fn, name=None):
super().__init__(name=name)
self._params = tree.map_structure_with_path(create_variable, params)
self._apply = jax2tf.convert(lambda p, x: apply_fn(p, None, x))
self._apply = tf.autograph.experimental.do_not_convert(self._apply)
def __call__(self, inputs):
return self._apply(self._params, inputs)
net = JaxModule(params, f.apply)
[v.name for v in net.trainable_variables]
[4]:
['jax_module/mlp/_/linear_0/b:0',
'jax_module/mlp/_/linear_0/w:0',
'jax_module/mlp/_/linear_1/b:0',
'jax_module/mlp/_/linear_1/w:0',
'jax_module/mlp/_/linear_2/b:0',
'jax_module/mlp/_/linear_2/w:0']
使用 TensorFlow 训练#
TensorFlow Datasets 是一个很棒的库,其中包含许多您可能想要用于研究的常见数据集。在这里,我们将使用它来加载 MNIST 手写数字数据集,并定义一个简单的 pipeline,它将随机打乱训练图像并将它们归一化为 [0, 1)。
[5]:
import tensorflow_datasets as tfds
ds_train, ds_test = tfds.load('mnist', split=('train', 'test'),
shuffle_files=True, as_supervised=True)
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
image = tf.cast(image, tf.float32) / 255.
return image, label
ds_train = ds_train.map(normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(60000)
ds_train = ds_train.batch(100)
ds_train = ds_train.repeat()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(100)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
为了训练我们的模型,我们需要一个训练循环,该循环根据某些损失的梯度更新模型参数。对于本例,我们将使用 Sonnet 的 Adam 优化器,并对每个 mini-batch 执行梯度更新到我们的参数。
[6]:
net = JaxModule(params, f.apply)
opt = snt.optimizers.Adam(1e-3)
@tf.function(experimental_compile=True, autograph=False)
def train_step(images, labels):
"""Performs one optimizer step on a single mini-batch."""
with tf.GradientTape() as tape:
images = snt.flatten(images)
logits = net(images)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=labels)
loss = tf.reduce_mean(loss)
params = tape.watched_variables()
loss += 1e-4 * sum(map(tf.nn.l2_loss, params))
grads = tape.gradient(loss, params)
opt.apply(grads, params)
return loss
for step, (images, labels) in enumerate(ds_train.take(6001)):
loss = train_step(images, labels)
if step % 1000 == 0:
print(f"Step {step}: {loss.numpy()}")
Step 0: 2.309901475906372
Step 1000: 0.23313118517398834
Step 2000: 0.058662284165620804
Step 3000: 0.060427404940128326
Step 4000: 0.07748399674892426
Step 5000: 0.07069656997919083
Step 6000: 0.03870276361703873
为了评估我们新训练的模型表现如何,我们可以使用测试集上的 top-1 准确率。
[7]:
def accuracy(model):
total = 0
correct = 0
for images, labels in ds_test:
predictions = tf.argmax(model(snt.flatten(images)), axis=1)
correct += tf.math.count_nonzero(tf.equal(predictions, labels))
total += images.shape[0]
print("Got %d/%d (%.02f%%) correct" % (correct, total, correct / total * 100.))
accuracy(net)
Got 9805/10000 (98.05%) correct
可视化模型对我们提供的输入的预测结果非常有用。当模型错误预测标签时,这尤其有用,您可以看到在某些情况下,笔迹有点可疑!
[8]:
import matplotlib.pyplot as plt
def sample(correct, rows, cols):
"""Utility function to show a sample of images."""
n = 0
f, ax = plt.subplots(rows, cols)
if rows > 1:
ax = tf.nest.flatten([tuple(ax[i]) for i in range(rows)])
f.set_figwidth(14)
f.set_figheight(4 * rows)
for images, labels in ds_test:
predictions = tf.argmax(net(snt.flatten(images)), axis=1)
eq = tf.equal(predictions, labels)
for i, x in enumerate(eq):
if x.numpy() == correct:
label = labels[i]
prediction = predictions[i]
image = tf.squeeze(images[i])
ax[n].imshow(image)
ax[n].set_title("Prediction:{}\nActual:{}".format(prediction, label))
n += 1
if n == (rows * cols):
break
if n == (rows * cols):
break
[9]:
sample(correct=True, rows=1, cols=5)
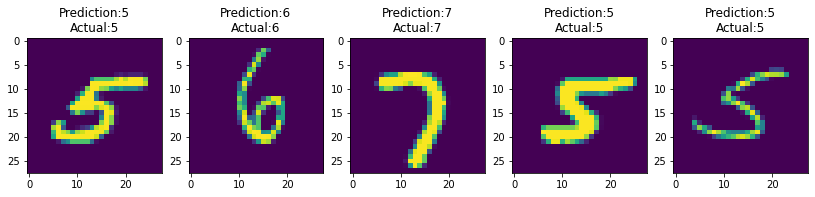
[10]:
sample(correct=False, rows=2, cols=5)

作为 TensorFlow SavedModel 保存到磁盘#
将使用 TensorFlow 训练的模型保存到磁盘作为“saved model”非常常见。这是一种语言独立的格式,允许您使用 Python、C++ 或 TensorFlow 支持的其他语言加载您的模型代码。
保存#
为了将我们的模型保存到磁盘,我们需要定义我们要保存的函数是什么,并提供对我们想要保存的任何状态的引用
[11]:
@tf.function(autograph=False, input_signature=[tf.TensorSpec([100, 28 * 28])])
def forward(x):
return net(x)
to_save = tf.Module()
to_save.forward = forward
to_save.params = list(net.variables)
tf.saved_model.save(to_save, "/tmp/example_saved_model")
INFO:tensorflow:Assets written to: /tmp/example_saved_model/assets
INFO:tensorflow:Assets written to: /tmp/example_saved_model/assets
加载#
加载 saved model 非常简单,您可以看到这看起来很像我们保存的模型
[12]:
loaded = tf.saved_model.load("/tmp/example_saved_model")
preds = loaded.forward(tf.ones([100, 28 * 28]))
assert preds.shape == [100, 10]
assert len(loaded.params) == 6
[v.name for v in loaded.params]
WARNING:tensorflow:Importing a function (__inference_forward_26770) with ops with custom gradients. Will likely fail if a gradient is requested.
WARNING:tensorflow:Importing a function (__inference_forward_26770) with ops with custom gradients. Will likely fail if a gradient is requested.
[12]:
['jax_module/mlp/_/linear_0/b:0',
'jax_module/mlp/_/linear_0/w:0',
'jax_module/mlp/_/linear_1/b:0',
'jax_module/mlp/_/linear_1/w:0',
'jax_module/mlp/_/linear_2/b:0',
'jax_module/mlp/_/linear_2/w:0']
值得庆幸的是,恢复后的模型表现与我们保存的模型一样好
[13]:
accuracy(loaded.forward)
Got 9805/10000 (98.05%) correct